
本庄弘
典
|
|
ドキュメントスキャナで本をスキャンした際、 画像のサイズが大きすぎるため保存に適しません。 この画像を2値画像とグレー スケール、 カラー画像それぞれの処理を加えることでファイルサイズを縮小し、 ニューラルネットを用いることによりある程度 自動化できないかと考えました。 今回はニューラルネットとして一般的な三層パーセプトロンを用いた画像判別の一例を解説し ます。
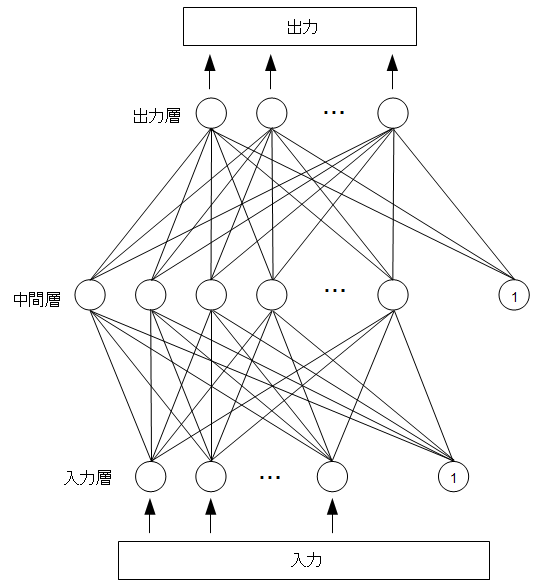
三層パーセプトロンは入力層、 中間層、 出力層と別れた三層の各ニューロンが重みと呼ばれる係数で結ばれたモデルとなり ます。
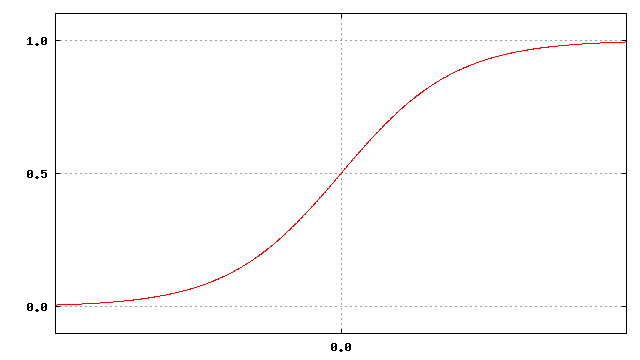
それぞれの重みは実数で表され、 パーセプトロンが機能するためにはこの重みが適切に設定されている必要があります。 ある 入力が与えられた際、 入力値に重みを掛け合わせ、 それぞれの合計に次のようなシグモイド関数を適用した数値を中間層の持 つ値とします。
|
|
各出力層も同様の計算がなされ、 パーセプトロンの出力が行われます。
多層パーセプトロンで適切な出力を行うための学習方法として一般的なものにバックプロパゲーションがあります。 バックプロ パゲーションではまず入力に対する正しい出力 (教師信号) を多数用意し、 各重みをランダムに設定します。 用意された入力に 対してランダムな重みからパーセプトロンの出力はでたらめな値となりますが、 この出力と教師信号との比較から 出力層と中間層の間の重みを修正し、 次いで中間層と入力層の重みを修正することで適切な重みを探し出し ます。
作成したパーセプトロンとバックプロパゲーションが正常に動作するかを確かめます。 次のような入力を用意しま した。
# 学習用教師信号ペア 0.40,0.20 0.60,0.20 0.30,0.20 0.50,0.10 0.80,0.10 0.90,0.70 0.20,0.10 0.30,0.10 0.50,0.50 1.00,0.00 0.60,0.20 0.80,0.40 # 評価用入力値 *0.50,0.10 *0.50,0.40 *0.10,0.40 |
入力値と教師信号のペアはタブ区切りの左が入力、 右が入力に対する教師信号です。 ここでは足し算と引き算の教師信号を与 えました。
実 行 し ま す 。
$ ./backprop.exe sample.txt 10000
0 0.87640153 100 0.26410368 200 0.10289131 300 0.03820243 400 0.02475167 ...(中略)... 9600 0.00077714 9700 0.00077174 9800 0.00076646 9900 0.00076128 0.4000, 0.2000 0.60, 0.18 0.60, 0.20 0.3000, 0.2000 0.50, 0.11 0.50, 0.10 0.8000, 0.1000 0.90, 0.70 0.90, 0.70 0.2000, 0.1000 0.30, 0.11 0.30, 0.10 0.5000, 0.5000 0.98, 0.02 1.00, 0.00 0.6000, 0.2000 0.80, 0.41 0.80, 0.40 0.5000, 0.1000 0.63, 0.35 0.5000, 0.4000 0.93, 0.06 0.1000, 0.4000 0.87, 0.00 Ratio=0.00075626 Count=10000 Sample=6 Input=2 Middle=4 Output=2 InputHidden0=-2.57936471,-2.20525001,-1.50656422,4.05055823,-0.66468037 InputHidden1=-1.29032439,8.71632107,-1.24344376,-0.85214732,-0.66468037 InputHidden2=2.04901840,-2.94096519,1.04866634,-1.98825291,0.29698485 HiddenOutput0=-2.91458436,-1.16992032 HiddenOutput1=5.84673832,-6.31188860 HiddenOutput2=-1.80018561,-0.42470539 HiddenOutput3=3.60356071,3.84028669 HiddenOutput4=1.40998866,-1.22885398 |
頼りないながらもそれなりの演算結果が出力されています。 評価として最後の数値は減算結果が負になるはずなのですが、 シ グモイド関数を通すことで出力が 0.0〜1.0 となるため正常な結果が得られません。
画像判別の入力値として次の値を使用しました。
この中から文章と絵の判別として画像の FFT を、 カラー画像の判別として HSV への変換を解説します。
縦書きの文章は横方向に一定の周波数を持っていると見なすことが出来ます。 これにより、 文章の画像を微分し FFT 処理を 行った結果から振幅を描画するとで、 明るく光る点が現れることがわかりました。
この点の明るさを入力値とすることで、 文章とイラストの判別が行えると期待できます。
カラー画像とモノクロ画像は画像の RGB を HSV に変換し、 色相から判別を行っています。
RGB のうちから最大のものを MAX、 最小のものを MIN とすると色相は次の式となります。
モノクロ画像は色相を持たないため、 RGB のうち青の成分を減らすことで黄色いフィルタをかけました。 こうする ことでモノクロ画像の色相の平均は黄色となり、 カラーとモノクロを判別するための入力値として期待でき ます。
ニューラルネットの学習は次の条件で行いました。
実際にこの条件で学習を行った際、 Core i7 950 で 7 時間弱の学習時間となりました。
作成されたツールで実際に判別を行い、 その精度を調べました。 評価に使用した本は学習に使われていないものを選びま した。
第
62 回東京エリア Debian 勉強会 2010 年 3 月
____________________________________________________________________________________________
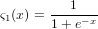

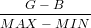 + 0
+ 0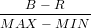 + 120
+ 120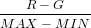 + 240
+ 240